Preparación examen (Práctica)
1. Se desea implementar una base de datos para el el sistema de gestión de peticiones e incidencias por parte de los clientes de una empresa de informática.
Actualmente, las peticiones e incidencias se reciben telefónicamente, por correo electrónico o en persona en alguno de los locales que tiene la empresa. La persona que atiende al teléfono o lee los correos electrónicos plantea una serie de preguntas al cliente y escribe en una plantilla de documento las respuestas. A continuación, se imprime el documento y se deja en una bandeja que recogen los técnicos cada mañana. A medida que los técnicos van avanzando en la solución de la incidencia (o han llamado al cliente para pedir más datos), van apuntando las acciones y el estado del problema en la hoja que recogieron, hasta que la incidencia queda resuelta. En ese momento, la dejan en una bandeja que recoge cada mañana el personal de administración, que se pone en contacto con el cliente y factura el importe correspondiente a las horas de trabajo y componentes sustituidos.
Sugiera un SGBD relacional para la base de datos. Argumente la decisión. Diseñe el esquema relacional de la base de datos conforme a la especificación facilitada. Indique todas aquellas restricciones que su esquema presenta y que los datos introducidos deben cumplir.
Tablas:
clientes:
id_cliente: primary key AUTO_INCREMENT (INT)
nombre (VARCHAR)
apellido (VARCHAR)
fecha_nacimiento (DATE)
DNI (VARCHAR)
tecnicos:
id_tecnico: primary key AUTO_INCREMENT (INT)
nombre (VARCHAR)
apellido (VARCHAR)
fecha_nacimiento (DATE)
DNI (VARCHAR)
incidencias:
id_incidencia: primary key AUTO_INCREMENT (INT)
id_cliente: foreign key de
clientes.id_cliente(INT)id_tecnico: foreign key de
tecnicos.id_tecnico(INT)tipo_recepcion (ENUM = ('telefónica', 'email', 'en persona'))
prioridad (ENUM = ('leve', 'evolucionable', 'grave'))
preguntas:
id_pregunta: primary key AUTO_INCREMENT (INT)
titulo (VARCHAR)
descripción (VARCHAR)
documento:
id_incidencia: primary key
id_pregunta: primary key
Estos dos atributos juntos forman la primary key y a su vez son foreign key:
id_incidencia: foreign key de
incidencias.id_incidenciaid_pregunta: foreign key de
preguntas.id_preguntarespuesta (VARCHAR)
acciones (VARCHAR)
estado (ENUM = ('recibida', 'en tratamiento', 'finalizada', 'anulada'))
fecha_fin (DATE)
facturas:
id_factura: primary key AUTO_INCREMENT (INT)
id_cliente: foreign key de
clientes.id_cliente(INT)id_incidencia: foreign key de
incidencias.id_incidencia(INT)precio_total (FLOAT)
Justifica la elección de tablas, esquemas, y cualquier decisión de diseño que elijas.
En este modelo de negocio se pueden visualizar varias tablas principales a primera vista (clientes, incidencias, técnicos y facturas)
Ademas, sabemos que una incidencia se complementa con una serie de preguntas que se realizan al cliente y sus respuestas son anotadas. Por tanto, podemos generar una tabla de preguntas para incorporar sus respuestas a la incidencia.
Con esto en mente, ya podemos ir justificando las tablas y sus relaciones:
Clientes <<crea>> Incidencias: En esta relación un cliente puede crear una o varias incidencias (1:N), pero una incidencia solo puede ser creada por un solo cliente (1:1), por lo tanto, esta relación es (1:N), con lo que no genera tabla y bastará con la propagación de la clave del cliente hacia la incidencia.
Incidencias <<tienen>> Preguntas: En esta relación una incidencia puede tener una o varias preguntas (1:N) y una pregunta puede pertenecer solo a una o varias incidencias (1:N), por lo tanto, esta relación es (M:N), con lo que genera una tabla nueva (documento), que relacionará las incidencias con las preguntas.
Técnicos <<atienden>> Incidencias: En esta relación un técnico puede atender una o varias incidencias (1:N), pero una incidencia puede ser atendida solo por un técnico (1:1), por lo tanto, esta relación es (1:N), con lo que no genera tabla y bastará con la propagación de la clave del técnico hacia la incidencia.
Incidencias <<generan>> Facturas: En esta relación una incidencia puede generar una sola factura (1:1) y una factura puede ser generada solo por una incidencia (1:1), por lo tanto, esta relación es (1:1), con lo que no genera tabla y bastará con la propagación de la clave de la incidencia hacia la factura.
2. Se desea implementar una base de datos para una nueva clínica sanitaria.
Se quiere guardar información sobre los médicos de la clínica, los pacientes, así como las citas. Sobre los médicos almacenará información: código identificación, nombre, apellidos, departamento, especialidad, dirección, teléfono, DNI, salario. De los pacientes se quiere guardar la siguiente información: código del paciente, nombre, apellidos, sexo, fecha de nacimiento, DNI, dirección, población, provincia, teléfono. Finalmente, de las citas se guardará la siguiente información: número de visita, fecha de visita, código del paciente, código del médico, motivo de visita, exploración, pruebas realizadas, diagnóstico.
Propón un esquema relacional y un esquema NoSQL para la implementación de dicha base de datos.
Justifica la elección de tablas, esquemas, y cualquier decisión de diseño que elijas.
¿Cuál de ellos consideras que es el más apropiado para el caso que se propone? ¿En qué condiciones aplicarías uno u otro?
3. Se quiere diseñar una base de datos para almacenar información sobre los asuntos que lleva un gabinete de abogados.
Cada asunto tiene un número de expediente que lo identifica, y corresponde a un solo cliente. Del asunto se debe almacenar el período (fecha de inicio y fecha de archivo o finalización), su estado (en trámite, archivado, etc.). Algunos asuntos son llevados por uno o varios abogados. De los abogados queremos saber su número de colegiado, nombre, apellidos, DNI, fecha de nacimiento. De los clientes guardaremos la información sobre: nombre, apellidos, DNI, domicilio, población, provincia, fecha de nacimiento, sexo.
En base a lo expuesto, se pide:
Sugiera un SGBD relacional para la base de datos. Argumente la decisión. Diseñe el esquema relacional de la base de datos conforme a la especificación facilitada. Indique todas aquellas restricciones que su esquema presenta y que los datos introducidos deben cumplir.
Tablas:
asuntos:
numero_expediente: primary key
id_cliente: foreign key (INT)
fecha_inicio (DATE)
fecha_archivo (DATE)
fecha_finalizacion (DATE)
estado (ENUM)
abogados_asuntos
numero_expediente: primary key (INT)
numero_colegiado: primary key (INT)
Estos dos atributos juntos forman la primary key y a su vez son foreign key:
numero_expediente: foreign key de
asuntos.numero_expediente(INT)numero_colegiado: foreign key de
abogados.numero_colegiado(INT)
abogados
numero_colegiado: primary key AUTO_INCREMENT (INT)
nombre (VARCHAR)
apellidos (VARCHAR)
DNI (VARCHAR)
fecha_nacimiento (DATE)
clientes
id_cliente: primary key AUTO_INCREMENT (INT)
id_poblacion: foreign key de
poblacion.id_poblacion(INT)nombre (VARCHAR)
apellidos (VARCHAR)
DNI (VARCHAR)
fecha_nacimiento (DATE)
domicilio (VARCHAR)
poblacion (VARCHAR)
provincia (VARCHAR)
sexo (ENUM)
provincia
id_provincia: primary key AUTO_INCREMENT (INT)
nombre (VARCHAR)
población
id_población: primary key AUTO_INCREMENT (INT)
id_provincia: foreign key de
provincia.id_provincia(INT)nombre (VARCHAR)
En este caso, la relación entre los abogados y los asuntos se establece entre la abogados_asuntos, la cual, al ser una relación M:N generá una nueva tabla que contiene los elementos
numero_expedienteynumero_colegiadoque forman una primary key compuesta.A su vez, los
clientestienen una relación "tiene" conasuntos, pero como cada asunto solo puede pertenecer a un cliente, es una relación 1:N, así que no es necesario crear otra tabla y bastara con propagar la clave a la tabla deasuntos.Para evitar duplicidad de datos en la tabla de
clientes, se crea la tablaprovinciasy la tablapoblaciones. Estas a su vez tienen una relación 1:N, con lo que propagamos la clave a la tablapoblaciones.
4. La empresa de alquiler de coches Rayo McRent quiere disponer de un sistema informático que le permita mantener el control de todos los alquileres que se realizan.
Para ello, han contratado a un consultor externo (usted) que deberá hacerse cargo del diseño de la base de datos que posteriormente nutrirá a dicho sistema. Esta empresa tiene la intención de desplegar toda la infraestructura necesaria en la nube pública de Amazon, Amazon Web Services, para reducir el esfuerzo de mantenimiento de la base de datos.
La empresa le ha indicado que quiere mantener registros de los siguientes datos:
Empleados (nombre, edad, fecha de nacimiento, documento de identidad, fecha de alta en la empresa, activo/no activo y número de alquileres realizados).
Alquileres (numero de contrato, estación de recogida, estación de entrega, nombre del conductor, email del conductor, empleado que gestiona el alquiler, coche asociado).
Coches (matricula, numero de bastidor, km recorridos, indicador de si está o no alquilado actualmente). Un empleado puede tener asignadas varias furgonetas.
Por otro lado, el sistema construido se nutrirá de la base de datos para realizar las siguientes consultas:
Obtener todos los empleados activos a final de mes para generar las nóminas.
xxxxxxxxxx31select *2from empleados3where estado = 'activo'Filtrar por los km recorridos de los coches, que pueden considerarse nuevos si su kilometraje es inferior a 50 km, usados si su kilometraje está entre 50 y 100 km y rodados si su kilometraje es superior a 100 km.
xxxxxxxxxx71select *,2case3when km < 50 then 'Nuevo'4when km >= 50 AND km <= 100 then 'Usado'5when km > 100 then 'Rodado'6end as estado7from cochesObtener información de coches de alquiler para una web y para que el contact center pueda facilitarla a los clientes.
xxxxxxxxxx21select *2from cochesObtener cada 20 minutos un listado de todos los coches que se encuentran sin alquilar.
No se pueden programar consultas automaticamente en SQL, así que esta automatización deberia realizarse utilizando un script en un lenguaje de programación de nuestra elección (Python, Java, etc.).
La consulta a realizar sería:
xxxxxxxxxx31select *2from coches3where estado = 'libre'
Además, el sistema construido generará y almacenará una factura PDF por cada alquiler realizado, disponible para el usuario que lo alquila. Si bien usted no es responsable de la generación de dicho archivo, si debe ofrecer una opción de almacenamiento para el mismo.
En base a lo expuesto, se pide:
Sugiera un SGBD relacional para la base de datos. Argumente la decisión. Diseñe el esquema relacional de la base de datos conforme a la especificación facilitada. Indique todas aquellas restricciones que su esquema presenta y que los datos introducidos deben cumplir.
Tablas:
empleados:
id_emp: primary key AUTO_INCREMENT (INT)
nombre (VARCHAR)
edad (INT)
fecha_nacimiento (DATE)
DNI (VARCHAR)
fecha_alta (DATE)
estado (ENUM)
numero_alquileres (INT)
alquileres
id_alq: primary key AUTO_INCREMENT (INT)
id_emp: foreign key de
empleados.id_emp(INT)id_car: foreign key de
coches.id_car(INT)numero_contrato (INT)
estacion_recogida (VARCHAR)
estacion_entrega (VARCHAR)
conductor (VARCHAR)
email (VARCHAR)
empleado_gestor (VARCHAR)
coche (VARCHAR)
coches
id_car: primary key AUTO_INCREMENT (INT)
matricula (VARCHAR)
numero_bastidor (VARCHAR)
km (INT)
estado (ENUM)
facturas:
id_fac: primary key AUTO_INCREMENT (INT)
id_alq: foreign key de
alquileres.id_alq(INT)
En este caso, la relación entre los empleados y los coches se establece entre la tabla alquileres, la cual, al ser una relación M:N generá una nueva tabla, en este caso alquileres, así que podriamos realizar todas las consultas propuestas con estas tres tablas.
Si quisieramos mejorar la base de datos, se podria agregar otra tabla para los clientes, eliminando los atributos (conductor, email) e introduciendo un nuevo atributo (id_cliente) como foreign key, ahorrando duplicados de clientes.
Identificar todos aquellos índices que deban ser creados en la base de datos, siempre que sea sensato teniendo en cuenta el coste de almacenamiento de los mismos, para satisfacer las necesidades del sistema. Indique el tipo (primario/secundario) de los mismos.
Para realizar las consultas propuestas podriamos crear un indice en el atributo alquilado de la tabla coches, así nos evitaríamos realizar un escaneo completo de la tabla al realizar la cuarta consulta.
Lo mismo pasa con la primera consulta, donde podríamos crear un índice en el atributo activo de la tabla empleados.
Podriamos crear algún indice extra si tubieramos que realizar ciertas consultas, por ejemplo:
Buscar un coche por matrícula: En este caso podriamos crear un nuevo indice en el atributo matrícula, evitándo el escaneo completo de la tabla para realizar la consulta.
Buscar un empleado por DNI: En este caso podriamos crear un nuevo indice en el atributo DNI, evitándo el escaneo completo de la tabla para realizar la consulta.
Conforme al esquema diseñado, indique el código SQL necesario para realizar una consulta que muestre el estado (alquilado/ no alquilado) del vehículo con menos kilometraje.
xxxxxxxxxx41select estado2from coches3order by km asc4limit 1¿Qué medidas de recuperación añadiría, proactivamente, a la especificación facilitada?
Yo añadiría un sistema de recuperación que contase con una replica de la base de datos en otra zona de disponibilidad diferente a la de la base de datos principal. Esta segunda base de datos estaria sincronizada con la base de datos principal pero se encontraría en standby, y en caso de ocurrir algun fallo en la base de datos principal, entraría en funcionamiento la replica de la base de datos.
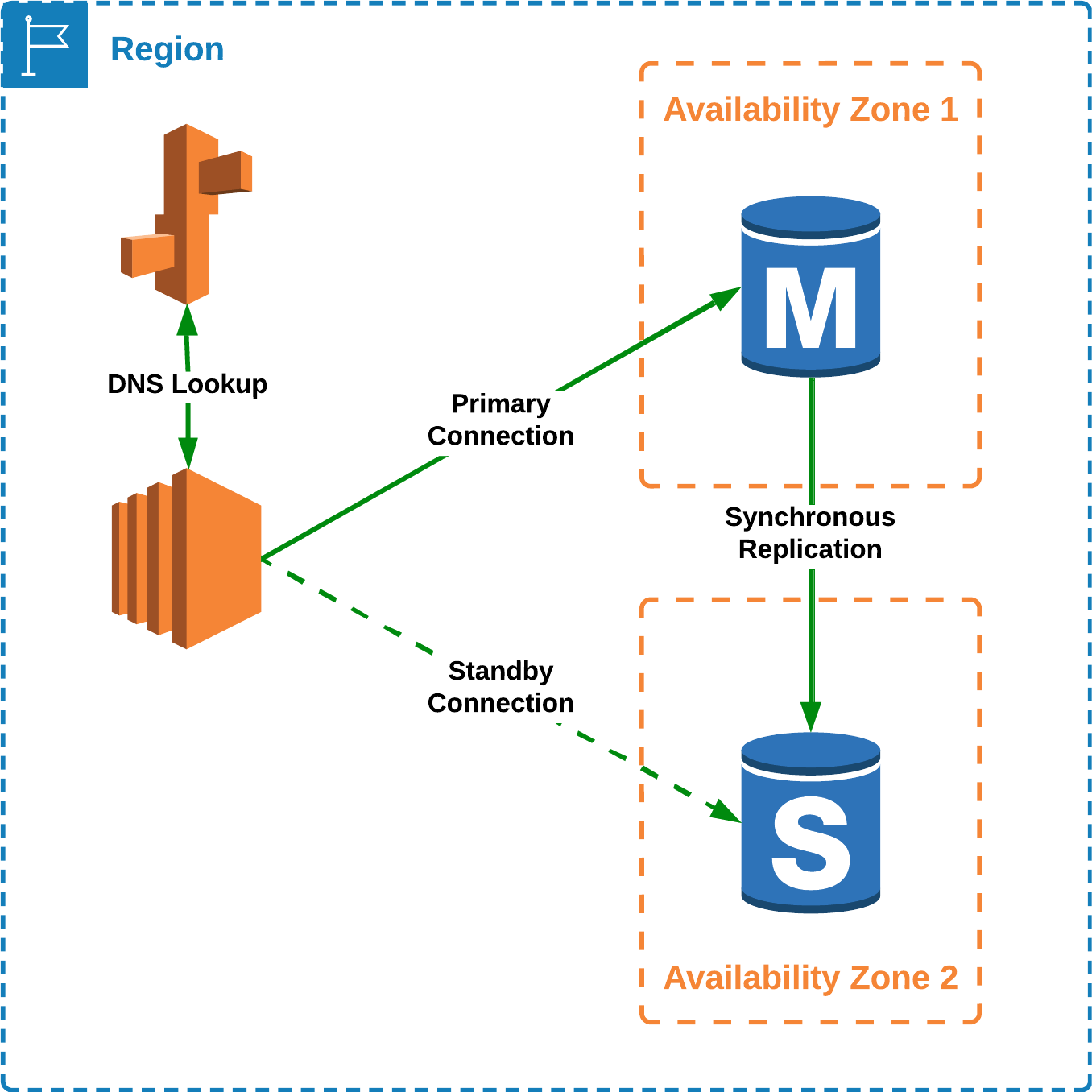
Base de datos principal con réplica en Standby Si los limites económicos no fueran un problema, agragaría otra base de datos adicional y plantearia una arquitectura CQRS (Command and Query Responsibity Segregation), donde dispondriamos de tres bases de datos, donde todas las consultas de escritura se realizarían a la base de datos principal, que a su vez se sincronizaria con las otras dos, donde una de ellas se mantendría en standby y la otra se encargaría de recibir las consultas de lectura.
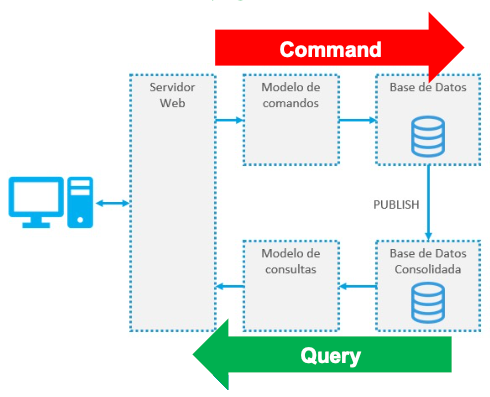
CQRS con dos bases de datos